What is Data Classification?
Data classification is the process of
categorizing and organizing data based on its
inherent characteristics, significance, and
sensitivity. This practice is essential for
gaining insights into the nature of the data
and enabling informed decisions on how to
monetize, govern, and safeguard information
assets.

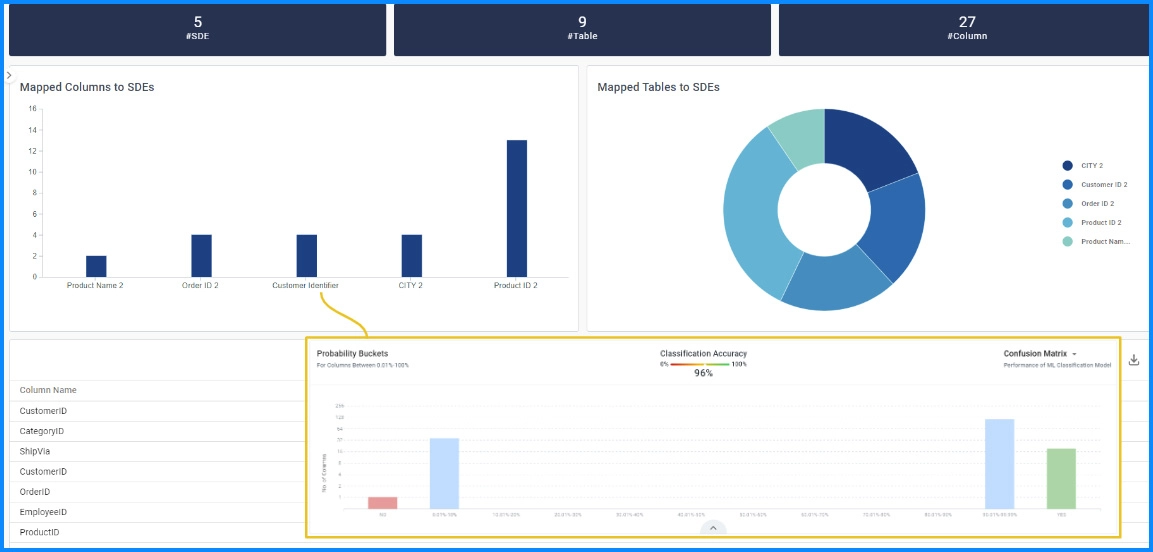
Machine Learning Classifies all Data assets quickly and at scale with >95% accuracy
Why Trust Global IDs with Your Data Classification?
Unrivaled Accuracy Using ML
Our Machine Learning algorithms learn from each click delivering >95% accuracy.
Automated Discovery of Sensitive Data
Our Transfer Learning technology automates the discovery of sensitive data elements out-of-the-box.
Empower Business Users
Our Classification tools empower business users by automatically linking business glossary terms with the respective database columns.
Industry Standard Ontologies
Our classification tools can standardize the semantic layer using Industry Standard Ontologies such as FIBO, FHIR & IDMP.
How Does Data Classification Benefit You?

Security and Regulatory
Compliance
Classified data uncovers the
location of sensitive data
allowing it to be protected.
This improves regulatory
compliance and reduces the
likelihood of theft.

Simplify Integration and
Interoperability
Classifying to a standard
ontology allows the
integration of data from
diverse sources to become
more straightforward. It also
promotes interoperability by
allowing different systems, applications, and components within and outside the firm to exchange data seamlessly.

Informed Decisions
Classification enables
organizations to understand
the location of their critical
data elements to make more
informed business decisions
and improve data
management strategies.